

空间序列工作记忆: 顺序和关系结构编码的发育和演化因素
来源:发布时间:2022-02-10
2022年2月2日,《The Journal of Neuroscience》第42卷第5期以封面文章的形式在线发表了题为《空间序列的工作记忆: 对于顺序和关系结构编码的发育和演化因素》的研究论文。该研究由中国科学院脑科学与智能技术卓越创新中心(神经科学研究所)、上海脑科学与类脑研究中心、中国科学院灵长类神经生物学重点实验室王立平研究组完成。该研究通过行为学分析和建模发现,成人、儿童和猕猴完成相同的空间序列任务时,不仅存在信息编码精度的差异,还存在对关系结构加工方式的差异——只有人类被试无论年龄大小都会自发地提取连续项目之间的抽象空间关系,并采用内化语言对工作记忆中的序列长度进行压缩。该研究直接定量评估了发育和演化对人类序列表征的相对贡献,这将有助于我们进一步理解和探索人类认知能力(例如语言处理)的独特性。
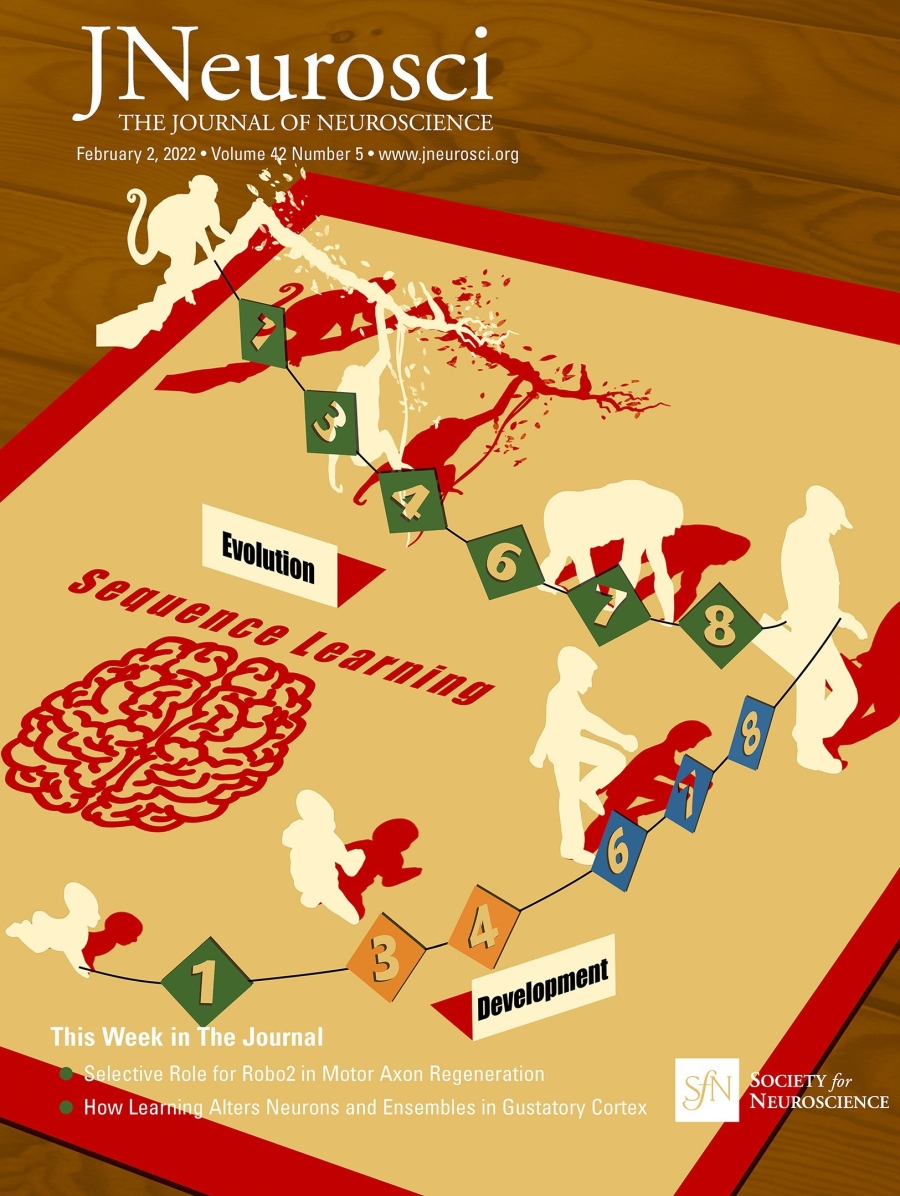
图1:《神经科学杂志》第42卷第5期封面:显示了应用于序列学习(数字字符串 1-3-4-6-7-8)的演化(上面的白色,从猕猴到人类)和发育(下面的白色,从婴儿到成人)因素。与猕猴不同,人类无论年龄大小都会自发地提取连续数字之间的关系,并使用组块化的策略压缩工作记忆中的序列。
人类的大多数行为,从眼动、走路、舞蹈、发声,再到抽象的文化创造——语言:例如阅读(自然语言)与数学(形式语言),都是按序列的形式来组织的。而在漫长的演化之路上,人类之所以能创造出形形色色的语言,说明同那些中途与人类分道扬镳的物种相比,我们对序列信息的表征和处理能力具有某些关键的独到之处。
一个简单的假设是,不同发育阶段的人类和其他物种对序列的加工方式相同,处理能力仅存在程度差异,例如:由工作记忆容量差异造成的信息编码精度的不同。
另外的假设则蕴含更多可能:人类和其他物种对序列信息的处理能力不只是量的不同,在某些层面还存在着质的不同。其中,“形式语法层面的超正则性构成了人类与其他物种之间的语法壁垒”曾是领域内的传统假说,而王立平研究组2018年发表在《Current Biology》上的研究论文,通过“延时序列生成任务”挑战了该假说,并提出了新的语言演化假说:人类在序列处理过程中使用到的某些特有的结构敏感算法,更有可能是人类之所以为人的独到而关键之处。具体而言,之前有证据表明:人类往往不是对序列中的单个项目进行逐一编码,而是自发地检测项目之间的某些关系结构,借此将它们压缩成更少的“组块”(chunk)来降低序列长度。目前,大家尚不清楚这种能力是否为人类所独有。
为了验证这些假设,王立平研究团队通过相同的空间序列生成任务测试了成人、儿童(6-7岁)和非人类灵长类动物(猕猴)的序列处理能力(图2)。

图2:延时序列生成任务的示意图。被试需要在刺激呈现阶段记忆目标点的空间位置和时间顺序信息,并在一段延迟后按呈现阶段的顺序依次汇报。
此前已经有一些计算模型和电生理学研究发现,序列中每个记忆项目的信息可以被拆分为该项目的固有特性(例如在该研究中的空间位置信息)和时间顺序信息这两种独立的成分,进行联合编码(conjunctive coding)——这或许就是大脑编码和保持完整序列信息的基础。研究人员依此建立了联合编码模型(图3)来定量评估第一种假设。该模型不仅可以反映首因-近因效应、换置错误率梯度变化曲线等行为学指标,其拟合参数也能很好地解释被试间的表现差异:空间位置和时间顺序的编码精度是导致儿童和猕猴表现较差的主要因素,而即使经过长期训练,猕猴也仍然显示出对序列信息的编码资源进行重新分配时的策略限制。
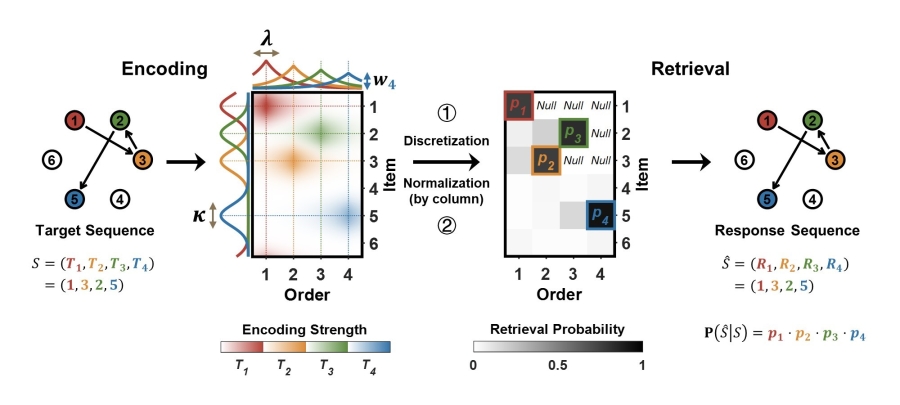
图3:联合编码模型示意图。模型分为两个阶段:在编码阶段,序列中的每一目标点都被拆分为独立的位置和顺序信息对应的分布,并组成联合分布,而所有目标点的联合分布最终再加权平均成为混合分布,用以刻画序列信息的总体编码强度;在检索阶段,混合分布经过离散化和归一化成为检索概率,从而可以计算出任意可能被汇报的序列的概率大小。其中,λ 和 κ 分别控制了顺序和位置信息的编码精度,而权重 {wi } 则控制了每个目标点联合分布的相对编码强度。
随后,为了检验第二种假设,研究人员将全部360种长度为4的序列按照旋转、镜像等刚体变换后统一的“图样”进行归类,得到了30种关系结构(图4AB)。进一步运用格式塔原则,将顺序和位置都临近的项目压缩为同一组块,30种图样就可以再归类为8种“组块模式”。对这些关系结构的正确率和反应时进行统计分析后发现:人类被试无论年龄大小都能自发地使用跨不同图样的通用分块策略来压缩序列信息,而猕猴则没有这种普遍特征。
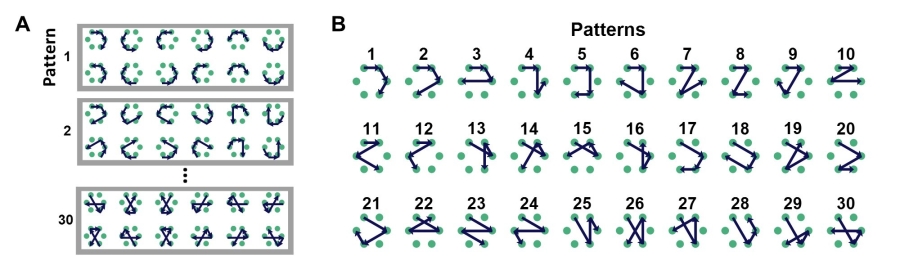
图4:(A)360种长度为4的序列。(B)30种图样。
最后,研究人员还将分块策略添加到了原始的联合编码模型当中,在关系结构层面解释了被试表现的差异;并且通过与添加其他替代策略的模型进行对比,证明分块策略确实能捕捉更多差异。
综上,通过跨物种比较研究,王立平研究组的工作为理解人类序列处理能力的起源和发育演变提供了新见解,将有助于查明人类认知能力的独特性——包括理解、学习和生成序列信息的能力,乃至其中最为重要的语言处理能力。
该项工作主要由中科院脑智卓越中心博士后甄艳芬和博士生张贺在王立平研究员指导下共同完成,余诗景、龙腾海、张冰倩、姜新剑、李俊汝、方文等研究组成员提供了重要帮助。研究得到远东宏信教育集团任国芳女士、谢雅芳女士,中科院脑智卓越中心动物房及研究组其他成员的大力协助。该研究获得了中科院、上海市和国家基金委的资助。